压缩策略
本质上只有两种"压缩"哲学:要么直接丢弃内容(截断/裁剪/剥离),要么用 AI 将其浓缩为摘要。
plain
上下文预算紧张程度: 低 ───────────────────────────────→ 高
策略 1: 工具输出截断 (始终生效)
策略 2: 工具输出裁剪 (prune, 旧输出标记清除)
策略 3: AI 摘要压缩 (compaction, 旧轮次 → 结构化摘要)
策略 4: 媒体剥离 (stripMedia, 移除图片/PDF)
策略 5: 溢出重放 (overflow replay, 剥离媒体后重试)策略 1:工具输出截断
ToolPart 给到 LLM 前要进行截取,最大 2000 字符。
typescript
// message-v2.ts
function truncateToolOutput(text, maxChars = 2000) {
if (!maxChars || text.length <= maxChars) return text
return `${text.slice(0, maxChars)}\n[Tool output truncated: omitted ${omitted} chars]`
}每个 ToolPart 的输出在给到 LLM 前都需要截断,最大 2000 字符
toModelMessagesEffect() 在构建消息时对所有完成的 tool part 统一截断到 TOOL_OUTPUT_MAX_CHARS (2000 字符)。
策略 2:工具输出裁剪
保留最近 2 轮 ToolPart 的完整输出,之前的 ToolPart 标记为 [Old tool result content cleared]
typescript
// compaction.ts
// goes backwards through parts until there are PRUNE_PROTECT tokens worth of tool
// calls, then erases output of older tool calls to free context space
const prune = Effect.fn("SessionCompaction.prune")(function* (input: { sessionID: SessionID }) {
const cfg = yield * config.get()
if (!cfg.compaction?.prune) return
log.info("pruning")
const msgs =
yield *
session
.messages({ sessionID: input.sessionID })
.pipe(Effect.catchIf(NotFoundError.isInstance, () => Effect.succeed(undefined)))
if (!msgs) return
let total = 0
let pruned = 0
const toPrune: MessageV2.ToolPart[] = []
let turns = 0
loop: for (let msgIndex = msgs.length - 1; msgIndex >= 0; msgIndex--) {
const msg = msgs[msgIndex]
if (msg.info.role === "user") turns++
// 保护最近 2 轮
if (turns < 2) continue
// 遇到已完成摘要的消息则停止 (已经压缩过了)
if (msg.info.role === "assistant" && msg.info.summary) break loop
for (let partIndex = msg.parts.length - 1; partIndex >= 0; partIndex--) {
const part = msg.parts[partIndex]
if (part.type !== "tool") continue
if (part.state.status !== "completed") continue
// 受保护的工具 【skill】 -> 不裁剪
if (PRUNE_PROTECTED_TOOLS.includes(part.tool)) continue
if (part.state.time.compacted) break loop
const estimate = Token.estimate(part.state.output)
total += estimate
if (total <= PRUNE_PROTECT) continue
// 累计超过 PRUNE_PROTECT(40000 tokens) 的旧输出 → 标记 compacted
pruned += estimate
toPrune.push(part)
}
}
log.info("found", { pruned, total })
// 总裁剪量 > PRUNE_MINIMUM(20000 tokens) 时才真正写入
if (pruned > PRUNE_MINIMUM) {
for (const part of toPrune) {
if (part.state.status === "completed") {
part.state.time.compacted = Date.now()
yield * session.updatePart(part)
}
}
log.info("pruned", { count: toPrune.length })
}
})- prune 不调用 AI,只是静默丢弃旧的工具输出文本
- 被标记后,在
toModelMessagesEffect()中输出变为"[Old tool result content cleared]"
策略 3: AI 摘要压缩
保留最近 2 轮,用 AI 将旧轮次压缩成结构化摘要.
plain
要求 AI 输出固定的 Markdown 结构:
## Goal — 单句任务总结
## Constraints & Preferences — 用户约束/偏好
## Progress
### Done — 已完成工作
### In Progress — 当前进行中
### Blocked — 阻塞项
## Key Decisions — 关键决策及原因
## Next Steps — 有序的后续步骤
## Critical Context — 重要技术事实、错误、待解决问题
## Relevant Files — 相关文件路径及原因策略 4: 媒体剥离
typescript
toModelMessagesEffect() 支持 stripMedia: true 选项。在 compaction 流程中:
// compaction.ts:504
const modelMessages = yield* MessageV2.toModelMessagesEffect(msgs, model, {
stripMedia: true, // 构建摘要 prompt 时剥离媒体
toolOutputMaxChars: TOOL_OUTPUT_MAX_CHARS,
})
将图片、PDF 等大体积附件从上下文中移除,只保留文本。策略 5: 溢出重放
plain
// overflow replay
当上下文即使压缩后仍然溢出(比如用户贴了一张巨大的图片),compaction 会尝试"重放":
1. 找到 compaction 之前的最后一个"正常"用户消息
2. 剥离媒体附件 → 替换为 "[Attached image/png: file]"
3. 将该消息作为新的 user 消息重新插入
4. 然后注入提示: "The previous request exceeded the provider's size
limit due to large media attachments. The conversation was
compacted and media files were removed from context..."
5. 让 Agent 继续执行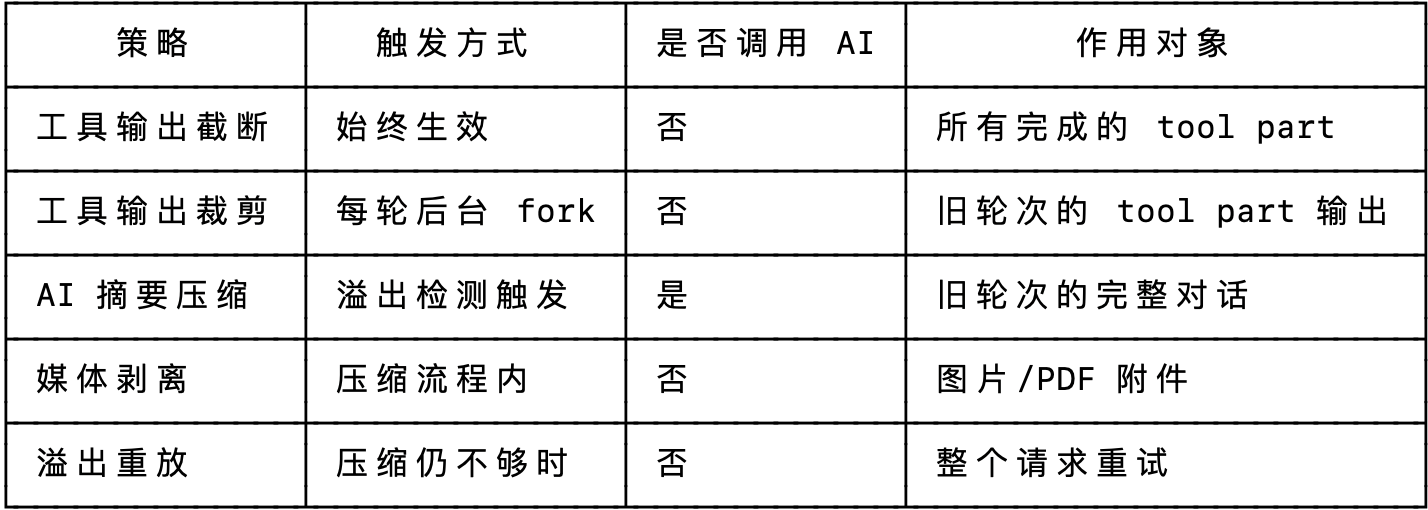
AI 摘要压缩
溢出检测
使用 AI 进行压缩的条件:AI Message 使用的 token 数 >= 可用上下文
检测溢出的时机:
- 流结束时(processor.ts):LLM 返回 finish 后,检查 usage.tokens,若溢出则设置 ctx.needsCompaction = true
- 每轮循环开始时(prompt.ts):检查 lastFinished.tokens,若溢出则插入 compaction 任务
typescript
// overflow.ts
const COMPACTION_BUFFER = 20_000
// 可用上下文 = 模型上下文 - 预留上下文
export function usable(input: { cfg: Config.Info; model: Provider.Model }) {
const context = input.model.limit.context
if (context === 0) return 0
const reserved =
input.cfg.compaction?.reserved ?? Math.min(COMPACTION_BUFFER, ProviderTransform.maxOutputTokens(input.model))
return input.model.limit.input
? Math.max(0, input.model.limit.input - reserved)
: Math.max(0, context - ProviderTransform.maxOutputTokens(input.model))
}
// token 数 >= 可用上下文 && 配置自动压缩(cfg.compaction.auto === true)
export function isOverflow(input: { cfg: Config.Info; tokens: MessageV2.Assistant["tokens"]; model: Provider.Model }) {
if (input.cfg.compaction?.auto === false) return false
if (input.model.limit.context === 0) return false
const count =
input.tokens.total || input.tokens.input + input.tokens.output + input.tokens.cache.read + input.tokens.cache.write
return count >= usable(input)
}消息选择
选择删除哪些消息、保留哪些消息
typescript
// 选择要保留的消息
// 选择逻辑:从后往前遍历轮次,在预算内尽可能保留更多轮次。
// 如果整轮放不下,调用 splitTurn() 在轮次内部寻找分割点(在 assistant 消息之间切分)。
const select = Effect.fn("SessionCompaction.select")(function* (input: {
messages: MessageV2.WithParts[]
cfg: Config.Info
model: Provider.Model
}) {
const limit = input.cfg.compaction?.tail_turns ?? DEFAULT_TAIL_TURNS
if (limit <= 0) return { head: input.messages, tail_start_id: undefined }
const budget = preserveRecentBudget({ cfg: input.cfg, model: input.model })
// 识别所有轮次
const all = turns(input.messages)
if (!all.length) return { head: input.messages, tail_start_id: undefined }
const recent = all.slice(-limit) // 最近 N 轮
const sizes = yield* Effect.forEach(
recent,
(turn) =>
estimate({
messages: input.messages.slice(turn.start, turn.end),
model: input.model,
}),
{ concurrency: 1 },
)
let total = 0
let keep: Tail | undefined
for (let i = recent.length - 1; i >= 0; i--) {
// 从后往前找可保留的轮次
const turn = recent[i]!
const size = sizes[i]
if (total + size <= budget) {
total += size
keep = { start: turn.start, id: turn.id }
continue
}
// 预算不够,尝试在轮次内分割
const remaining = budget - total
const split =
yield *
splitTurn({
messages: input.messages,
turn,
model: input.model,
budget: remaining,
estimate,
})
if (split) keep = split
else if (!keep) log.info("tail fallback", { budget, size, total })
break
}
if (!keep || keep.start === 0) return { head: input.messages, tail_start_id: undefined }
return {
head: input.messages.slice(0, keep.start), // // 要删除的旧消息
tail_start_id: keep.id, // 保留的起始 ID
}
})plain
// select
Messages: [U1, A1, U2, A2, U3, A3, U4, A4, U5, A5]
↓ turns() 识别轮次
Turns: [T1: U1-A1, T2: U2-A2, T3: U3-A3, T4: U4-A4, T5: U5-A5]
↓ 保留最近 N 轮 (默认 2) + 预算限制
保留: T4: U4-A4, T5: U5-A5
↓
返回: { head: [U1..A3], tail_start_id: U4.id }
↑ 要被摘要替换的 ↑ 保留的起点一个轮次:以 user message 为边界【user message + 多条 ai message】
typescript
// 识别对话轮次
function turns(messages: MessageV2.WithParts[]) {
const result: Turn[] = []
for (let i = 0; i < messages.length; i++) {
const msg = messages[i]
if (msg.info.role !== "user") continue
if (msg.parts.some((part) => part.type === "compaction")) continue
result.push({
start: i,
end: messages.length,
id: msg.info.id,
})
}
// 当前轮次 end 为 下一轮次的 start
for (let i = 0; i < result.length - 1; i++) {
result[i].end = result[i + 1].start
}
return result
}
/**
Messages: [User1, Assistant1, User2, Assistant2, User3, Assistant3]
↓ ↓ ↓ ↓
Turns: [Turn1] [Turn2] [Turn3]
Turn1: { start: 0, end: 2, id: User1.id }
Turn2: { start: 2, end: 4, id: User2.id }
Turn3: { start: 4, end: 6, id: User3.id }
*/typescript
function preserveRecentBudget(input: { cfg: Config.Info; model: Provider.Model }) {
return (
input.cfg.compaction?.preserve_recent_tokens ??
Math.min(MAX_PRESERVE_RECENT_TOKENS, Math.max(MIN_PRESERVE_RECENT_TOKENS, Math.floor(usable(input) * 0.25)))
)
}
// 预算计算 (preserveRecentBudget()):
// budget = cfg.compaction?.preserve_recent_tokens
// ?? clamp(usable * 0.25, MIN=2000, MAX=8000)
// 即默认保留模型可用上下文的 25% 给近期消息。typescript
// 在轮次内找到可分割点
function splitTurn(input: {
messages: MessageV2.WithParts[]
turn: Turn
model: Provider.Model
budget: number
estimate: (input: { messages: MessageV2.WithParts[]; model: Provider.Model }) => Effect.Effect<number>
}) {
return Effect.gen(function* () {
if (input.budget <= 0) return undefined
if (input.turn.end - input.turn.start <= 1) return undefined
for (let start = input.turn.start + 1; start < input.turn.end; start++) {
const size = yield* input.estimate({
messages: input.messages.slice(start, input.turn.end),
model: input.model,
})
if (size > input.budget) continue
return {
start,
id: input.messages[start]!.info.id,
} satisfies Tail
}
return undefined
})
}AI 摘要生成
typescript
// 压缩 config
export const PRUNE_MINIMUM = 20_000 //修剪最小阈值(token)
export const PRUNE_PROTECT = 40_000 // 修剪保护阈值
const TOOL_OUTPUT_MAX_CHARS = 2_000 // 工具输出最大字符数
const PRUNE_PROTECTED_TOOLS = ["skill"] // 受保护的工具
const DEFAULT_TAIL_TURNS = 2 // 默认保留最近 2 轮
const MIN_PRESERVE_RECENT_TOKENS = 2_000 // 最小保留近期 token
const MAX_PRESERVE_RECENT_TOKENS = 8_000 // 最大保留近期 token
// 摘要模板,要求 AI 以固定格式输出
const SUMMARY_TEMPLATE = `Output exactly the Markdown structure shown inside <template> and keep the section order unchanged. Do not include the <template> tags in your response.
<template>
## Goal
- [single-sentence task summary]
## Constraints & Preferences
- [user constraints, preferences, specs, or "(none)"]
## Progress
### Done
- [completed work or "(none)"]
### In Progress
- [current work or "(none)"]
### Blocked
- [blockers or "(none)"]
## Key Decisions
- [decision and why, or "(none)"]
## Next Steps
- [ordered next actions or "(none)"]
## Critical Context
- [important technical facts, errors, open questions, or "(none)"]
## Relevant Files
- [file or directory path: why it matters, or "(none)"]
</template>
Rules:
- Keep every section, even when empty.
- Use terse bullets, not prose paragraphs.
- Preserve exact file paths, commands, error strings, and identifiers when known.
- Do not mention the summary process or that context was compacted.`
// 构建prompt
function buildPrompt(input: { previousSummary?: string; context: string[] }) {
const anchor = input.previousSummary
? [
"Update the anchored summary below using the conversation history above.",
"Preserve still-true details, remove stale details, and merge in the new facts.",
"<previous-summary>",
input.previousSummary,
"</previous-summary>",
].join("\n")
: "Create a new anchored summary from the conversation history above."
return [anchor, SUMMARY_TEMPLATE, ...input.context].join("\n\n")
}
// 执行压缩
const processCompaction = Effect.fn("SessionCompaction.process")(function* (input: {
parentID: MessageID
messages: MessageV2.WithParts[]
sessionID: SessionID
auto: boolean
overflow?: boolean
}) {
const parent = input.messages.findLast((m) => m.info.id === input.parentID)
if (!parent || parent.info.role !== "user") {
throw new Error(`Compaction parent must be a user message: ${input.parentID}`)
}
const userMessage = parent.info
const compactionPart = parent.parts.find((part): part is MessageV2.CompactionPart => part.type === "compaction")
let messages = input.messages
let replay:
| {
info: MessageV2.User
parts: MessageV2.Part[]
}
| undefined
if (input.overflow) {
const idx = input.messages.findIndex((m) => m.info.id === input.parentID)
for (let i = idx - 1; i >= 0; i--) {
const msg = input.messages[i]
if (msg.info.role === "user" && !msg.parts.some((p) => p.type === "compaction")) {
replay = { info: msg.info, parts: msg.parts }
messages = input.messages.slice(0, i)
break
}
}
const hasContent =
replay && messages.some((m) => m.info.role === "user" && !m.parts.some((p) => p.type === "compaction"))
if (!hasContent) {
replay = undefined
messages = input.messages
}
}
const agent = yield* agents.get("compaction")
const model = agent.model
? yield* provider.getModel(agent.model.providerID, agent.model.modelID)
: yield* provider.getModel(userMessage.model.providerID, userMessage.model.modelID)
const cfg = yield* config.get()
const history = compactionPart && messages.at(-1)?.info.id === input.parentID ? messages.slice(0, -1) : messages
const prior = completedCompactions(history)
const hidden = new Set(prior.flatMap((item) => [item.userIndex, item.assistantIndex]))
const previousSummary = prior.at(-1)?.summary
const selected = yield* select({
messages: history.filter((_, index) => !hidden.has(index)),
cfg,
model,
})
// Allow plugins to inject context or replace compaction prompt.
const compacting = yield* plugin.trigger(
"experimental.session.compacting",
{ sessionID: input.sessionID },
{ context: [], prompt: undefined },
)
// 构建 Prompt
const nextPrompt = compacting.prompt ?? buildPrompt({ previousSummary, context: compacting.context })
const msgs = structuredClone(selected.head)
yield* plugin.trigger("experimental.chat.messages.transform", {}, { messages: msgs })
const modelMessages = yield* MessageV2.toModelMessagesEffect(msgs, model, {
stripMedia: true,
toolOutputMaxChars: TOOL_OUTPUT_MAX_CHARS,
})
const ctx = yield* InstanceState.context
const msg: MessageV2.Assistant = {
id: MessageID.ascending(),
role: "assistant",
parentID: input.parentID,
sessionID: input.sessionID,
mode: "compaction",
agent: "compaction",
variant: userMessage.model.variant,
summary: true,
path: {
cwd: ctx.directory,
root: ctx.worktree,
},
cost: 0,
tokens: {
output: 0,
input: 0,
reasoning: 0,
cache: { read: 0, write: 0 },
},
modelID: model.id,
providerID: model.providerID,
time: {
created: Date.now(),
},
}
yield* session.updateMessage(msg)
const processor = yield* processors.create({
assistantMessage: msg,
sessionID: input.sessionID,
model,
})
// 调用 Agent 生成摘要
const result = yield* processor.process({
user: userMessage,
agent,
sessionID: input.sessionID,
tools: {},
system: [],
messages: [
...modelMessages,
{
role: "user",
content: [{ type: "text", text: nextPrompt }],
},
],
model,
})
if (result === "compact") {
processor.message.error = new MessageV2.ContextOverflowError({
message: replay
? "Conversation history too large to compact - exceeds model context limit"
: "Session too large to compact - context exceeds model limit even after stripping media",
}).toObject()
processor.message.finish = "error"
yield* session.updateMessage(processor.message)
return "stop"
}
if (compactionPart && selected.tail_start_id && compactionPart.tail_start_id !== selected.tail_start_id) {
yield *
session.updatePart({
// 更新 compaction part 的 tail_start_id
...compactionPart,
tail_start_id: selected.tail_start_id,
})
}
if (result === "continue" && input.auto) {
if (replay) {
const original = replay.info
const replayMsg = yield* session.updateMessage({
id: MessageID.ascending(),
role: "user",
sessionID: input.sessionID,
time: { created: Date.now() },
agent: original.agent,
model: original.model,
format: original.format,
tools: original.tools,
system: original.system,
})
for (const part of replay.parts) {
if (part.type === "compaction") continue
const replayPart =
part.type === "file" && MessageV2.isMedia(part.mime)
? { type: "text" as const, text: `[Attached ${part.mime}: ${part.filename ?? "file"}]` }
: part
yield* session.updatePart({
...replayPart,
id: PartID.ascending(),
messageID: replayMsg.id,
sessionID: input.sessionID,
})
}
}
if (!replay) {
const info = yield* provider.getProvider(userMessage.model.providerID)
if (
(yield* plugin.trigger(
"experimental.compaction.autocontinue",
{
sessionID: input.sessionID,
agent: userMessage.agent,
model: yield* provider.getModel(userMessage.model.providerID, userMessage.model.modelID),
provider: {
source: info.source,
info,
options: info.options,
},
message: userMessage,
overflow: input.overflow === true,
},
{ enabled: true },
)).enabled
) {
const continueMsg = yield* session.updateMessage({
id: MessageID.ascending(),
role: "user",
sessionID: input.sessionID,
time: { created: Date.now() },
agent: userMessage.agent,
model: userMessage.model,
})
const text =
(input.overflow
? "The previous request exceeded the provider's size limit due to large media attachments. The conversation was compacted and media files were removed from context. If the user was asking about attached images or files, explain that the attachments were too large to process and suggest they try again with smaller or fewer files.\n\n"
: "") +
"Continue if you have next steps, or stop and ask for clarification if you are unsure how to proceed."
yield* session.updatePart({
id: PartID.ascending(),
messageID: continueMsg.id,
sessionID: input.sessionID,
type: "text",
// Internal marker for auto-compaction followups so provider plugins
// can distinguish them from manual post-compaction user prompts.
// This is not a stable plugin contract and may change or disappear.
metadata: { compaction_continue: true },
synthetic: true,
text,
time: {
start: Date.now(),
end: Date.now(),
},
})
}
}
}
if (processor.message.error) return "stop"
if (result === "continue") yield* bus.publish(Event.Compacted, { sessionID: input.sessionID })
return result
})消息过滤
typescript
消息过滤 filterCompacted() (message-v2.ts:1105-1133)
这是加载历史消息时的过滤器,确保已压缩的旧消息不会被送入 LLM:
遍历消息流(从旧到新):
1. 找到 "已完成摘要" 的 user 消息(其对应的 assistant 有 summary=true + finish + 无 error)
2. 在这些 user 消息中找到 CompactionPart
3. 读取 tail_start_id → 只保留 tail_start_id 之后的消息
4. 丢弃 tail_start_id 之前的所有消息
压缩前加载: [U1, A1, U2, A2, U3, A3, U4-C, A4(summary), U5, A5]
↑ CompactionPart
tail_start_id=U5.id
压缩后加载: [U4-C, U5, A5]
↑ 保留 CompactionPart 做标记
U1..A3 被丢弃完整流程
plain
┌─────────────────────────────────────────────────────┐
│ runLoop 每一轮 │
│ │
│ 1. filterCompacted() 过滤已压缩的旧消息 │
│ 2. 检查消息流中是否有 compaction part │
│ ├─ 有 → process() 执行压缩生成摘要 │
│ └─ 无 → 检查 isOverflow() │
│ ├─ 溢出 → create() 插入 compaction part │
│ └─ 正常 → 继续 LLM 调用 │
│ 3. LLM 流结束 → processor 检查 tokens 是否溢出 │
│ └─ 溢出 → needsCompaction=true → 返回 "compact" │
│ → prompt.ts 插入 compaction part │
│ 4. prune() 裁剪旧工具输出(后台 fork) │
│ │
│ 循环直到: finish="stop" 且无 tool calls 且无溢出 │
└─────────────────────────────────────────────────────┘